



Cloud Amputation
Back in May I started a project to reduce my dependence on 3rd party cloud services, especially those that I think have degraded in quality or are likely to misuse my personal information.
This all started with growing frustrations around the plethora of Google services that I had grown dependent upon. Julie and I migrated away from Gmail several years ago, with me moving first in a short dalliance with Hey email. I wasn’t at all pleased with how Hey rolled out their support for custom domains, so after some research I settled on Fastmail and migrated our personal accounts to that platform. We’ve been there for over a year and are extremely happy. Email is such a core service that I don’t mind paying for high availability and trustworthy security and privacy.
My motivation to sever my cloud ties more broadly started with Google charging for my legacy “Apps for Domain” support. I’m sure I didn’t read the fine print when they changed their terms, but I gradually started losing access to some legacy documents I was keeping in GDrive. Even after an attempted extract and archive of everything there, I still found that some docs were forever lost. This gave me pause: what else do I have locked up in someone else’s proprietary infrastructure that I could easily lose with simple change in terms of service?
Around this time I also heard the latest Tim Ferriss podcast with Derek Sivers. Derek went into detail on his journey on achieving tech independence, and even composed a how-to guide. I was inspired to make my own changes.
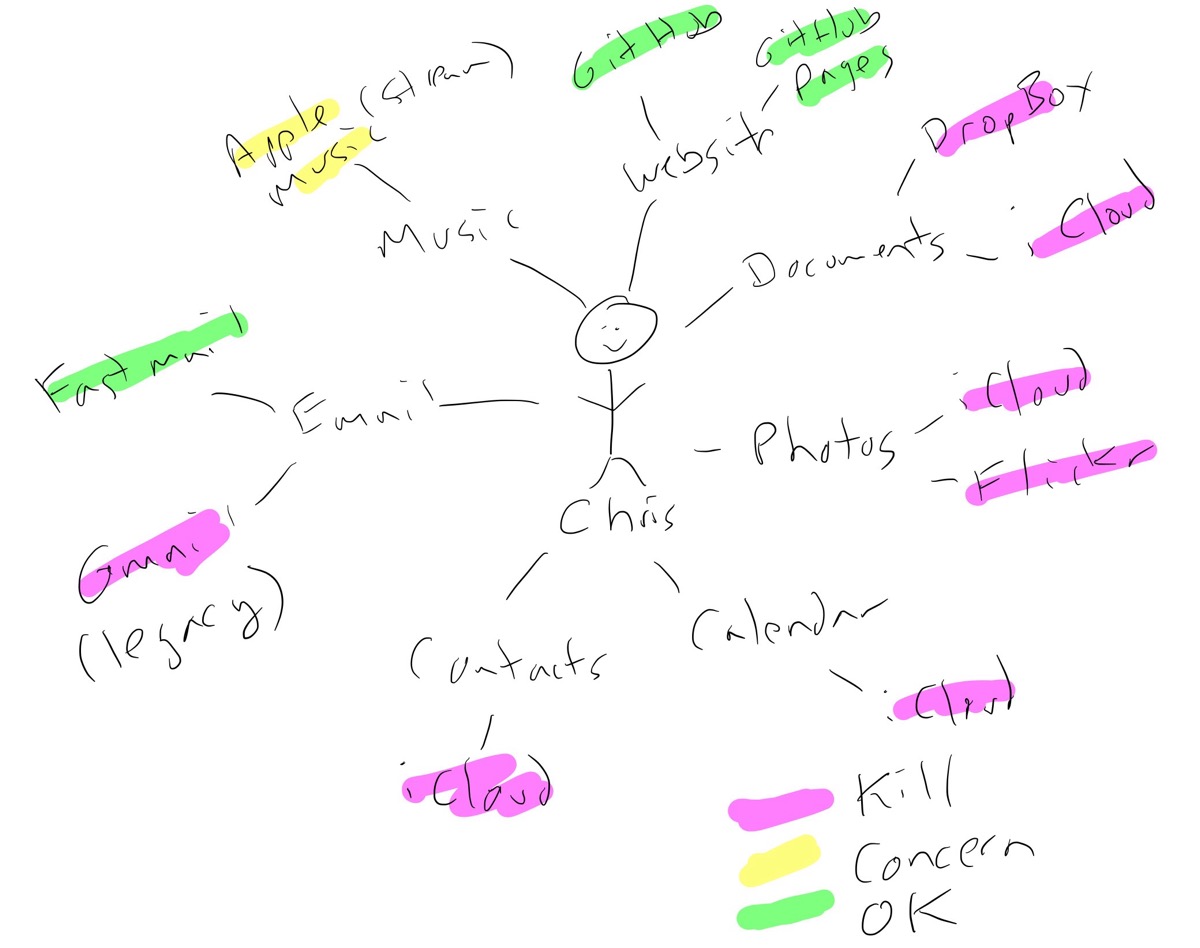 My cloud architecture sketch
My cloud architecture sketch
I sketched out the drawing above as a first step in creating an inventory of my dependencies. I booted up a project in Obsidian and dove right in.
Setting up my server and encrypted file sync
I somewhat reluctantly followed Sivers’ advice to setup an OpenBSD server on Vultr with attached encrypted storage. My reluctancy was driven by unfamiliarity with OpenBSD – I have nearly 40 years of Unix experience, but very little on OpenBSD. Almost all of teaching I do that is Unix based is on Ubuntu Linux. So it was a tradeoff between going off the reservation re: his advice, or sharpening my skills on OpenBSD. I chose the latter.
My first goal was to eliminate my dependence on DropBox for sync and file backup. The mechanics of this were simple, but I spent a lot of time on my macOS file system organizing and ensuring I wasn’t backing up items that don’t need to be in a private encrypted storage model. I roughly follow the PARA method for organizing my files and work; this certainly helped but I found some inconsistencies in decisions I had made early on. I also decided that digital assets like photos I’ve taken (digital photos going back to about 1995) wouldn’t live in this system. Too many files, too much storage, and not sensitive enough to require encrypted storage.
While Sivers gives excellent shell commands to get you started with synchronization and automation, I took things a bit further and wrote my own scripts and cron jobs. I’ll include them as I go through my narrative. This job runs every 30 minutes on my MacBook:
#!/usr/bin/env bash
# Configure these variables to your reality
REMOTE_HOST=chris@foo.bar
REMOTE_FOLDER=/mnt/
LOCAL_FOLDER=/Users/chrisbrooks/Documents/files.chrisbrooks/
# Print the time for logging purposes
echo "Running backup: $(date)"
# sync the files
rsync -avz --del --exclude ".DS_Store" "$LOCAL_FOLDER" "$REMOTE_HOST:$REMOTE_FOLDER"
# blank line to keep the logs clean
echo ""
Calendar and Contacts
This took longer than it should have because I skipped the “Web Server” step in Sivers’ guide because I had no intention (yet) of moving any of my web content to the private server. But of course Radicale (the CalDAV and CardDAV server) requires a web server to provide its services – doh! After rectifying this problem everything was up and running. I migrated my iCloud contacts and calendars to Radicale and then enabled change tracking and GitHub integration on the server. This is a nice backup mechanism: there are hooks built in to Radicale that make it trivial to do revision tracking in Git. This means that the underlying storage for contacts and calendar are simple file-system based, and I have a running change log in my private GitHub repository. The changes get committed to the local repo, then nightly I run. this script on the server:
#!/bin/sh
cd /var/db/radicale/collections
doas git add -A && (git diff --cached --quiet || git commit -m "Checkpoint $(date)")
git push
Heavy Reference Data, Photos, and Movies
This took more research and quite a bit of bandwidth. In addition to my large collection of digital photos, I have a lot of home movies, football film, tutorials that I’ve saved over the years (golf, sailing, etc.), and reference documents (mostly PDFs). These don’t require encryption, will rarely if ever change, but I want them both backed up and available on demand as individual files. I’ve used Backblaze for years for offsite backup, but that’s insufficient for the fine-grained on demand access I require for these files.
My solution was to use Backblaze B2, their cloud storage equivalent to Amazon’s S3. Even better, if I coupled B2 with Cloudflare’s CDN and proxying (I’m already a Cloudflare customer) then I could avoid some of the bandwidth charges for serving up the content. It took about 3 days to get everything loaded in B2, but the results are very satisfying. I can even embed objects I’ve put there in my local Obsidian documents.
I use the outstanding rclone tool to keep my media synchronized, again with a cron job that runs a script hourly:
#!/usr/bin/env bash
# Configure these variables to your reality
REMOTE_HOST=b2-foobar-media
REMOTE_FOLDER=brooks-media
LOCAL_FOLDER="/Volumes/Extreme SSD/To-Sync"
# Print the time for logging purposes
echo "Running sync to b2: $(date)"
# sync the files
rclone sync -P --exclude ".DS_Store" "$LOCAL_FOLDER" "$REMOTE_HOST:$REMOTE_FOLDER"
# blank line to keep the logs clean
echo ""
Backing up my iCloud photos
I should note that I don’t have the same distrust or distaste for Apple’s iCloud as I do for Google or DropBox. That said, I was a huge proponent of DropBox starting in about 2008, and was “all in” on Google’s cloud services up until about 3-4 years ago. I hope I feel this good about Apple in 10 years, but I don’t want to count on that.
I estimate that 95% of the photos I take and keep are from my iPhone, and those eventually find their way into iCloud. There’s an excellent open source tool called iCloud Photos Downloader that took just a few minutes to get working. I automated this with a nightly job:
icloudpd --directory "/Volumes/Extreme SSD 1/To-Sync/2. Areas/Photos/iCloudPhotos" --username foo@bar.org
Self-Hosting my Blog
When I moved my blog from Bluehost and Wordpress to a statically generated Jekyll site, I used the simple GitHub Pages automation to host and rebuild the site as needed. I’m mostly OK with GitHub pages running things for me, but in the long run serving a simple HTML site is a perfect (and trivial) step to take as long as I’m running my own server. I’m still not 100% thrilled with how this works because I rely on automated rebuilds when I’m writing frequently (such as our recent Europe trip where I posted almost every day for over 2 months).
Ultimately I’d like to use a git hook to have my server perform the rebuild whenever I commit to GitHub, but I haven’t dedicated the time yet to make sure I have everything setup properly to handle this. In the meantime I’m using Buddy to automate the build and copy process. The copy process is heavier than it needs to be: a full SFTP transfer of the entire site. I’d like it to be a smarter rsync process, but I’m unsure for now how to properly setup a locked down environment to do this securely. My lack of OpenBSD chops are showing here.
Obsidian Sync
I need Obsidian to sync between my desktop, iPad, and iPhone. I routinely hop between all three platforms in a given day because Obsidian is my task environment as well as my PKM environment. Obsidian works with plain text Markdown files, so moving to Git and GitHub were a logical step. I never liked how iCloud sync worked anyways: if there were a lot of changes to sync, it seemed indeterminate if sync was done or not and how conflicts would be resolved. I moved my vault into a private GitHub repository, use Working Copy on my iPad and iPhone, and followed this excellent guide to automate the process on my iPad and iPhone.
Can Anybody Do This?
I suppose the answer is “yes” – just follow Derek’s guide and you’ll probably get it all working. That said, I’m skeptical that this is a good path for the non-nerd everyday user. It is one thing to get something like this working, it is entirely a different matter to keep it working and well maintained. I have a recurring monthly task to manage the server and keep it updated. I’m familiar with setting up SSH keys, and managing the keys securely.
While I do plan to help Julie migrate away from iCloud, DropBox (I already helped her move from Evernote to Obsidian), I wouldn’t expect her to set it up properly or maintain it. I don’t mind doing the work because it helps keep me fresh on a variety of technologies, and because I enjoy automating stuff like this.



